Removing Phantom Container Volume in vSphere 6.7u3
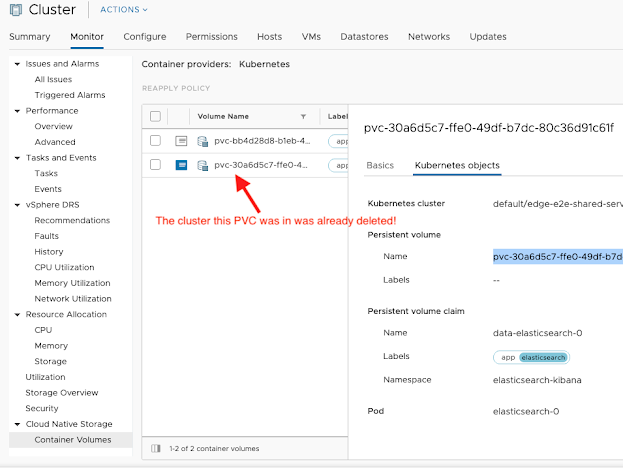
I've been playing around with Tanzu Kubernetes Grid on my vSphere 6.7u3 home lab setup, and so I've been creating and deleting clusters a lot lately. In browsing around vCenter, I noticed a new section in the Cluster and Datastore "Monitor" section called "Cloud Native Storage -> Container Volumes" that shows me all the persistent volumes that have been created with the more recent vSphere CSI Driver. Since I had been setting up my clusters with a default storage class like the following, I was now also able to visualize those volumes in the vCenter UI which is pretty neat: kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: vsphere-sc annotations: storageclass.kubernetes.io/is-default-class: "true" provisioner: csi.vsphere.vmware.com parameters: storagepolicyname: "k8s Storage Policy" fstype: ext3 The new CSI based plugin (https://github.com/kubernetes-sigs/vsphere-csi-driver/issues/251 ) allows you to sim